Windows-Platzhalter und reguläre Windows-Ausdrücke
Windows-Platzhalter können Sie eine Datei oder eine Gruppe von Dateien angeben, indem Sie einen Teil des Dateinamens eingeben. Das entsprechende Verzeichnis wird durchsucht, um alle Dateien zu finden, die dem Teilnamen entsprechen. Sie können auch verwenden reguläre Ausdrücke verwenden um Dateien bei der Verwendung anzugeben TCC (siehe unten).
Zur Angabe der Dateien werden üblicherweise Platzhalter verwendet sollte durch einen Befehl verarbeitet werden. Wenn Sie angeben müssen, welche Dateien verwendet werden sollen nicht verarbeitet werden, siehe Dateiausschlussbereiche (Für TCC interne Befehle), oder AUSSER (für externe Befehle).
Die meisten internen Befehle in TCC oder CMD akzeptieren Dateinamen mit Platzhaltern überall dort, wo ein vollständiger Dateiname verwendet werden kann. Es gibt zwei Platzhalterzeichen, das Sternchen * und das Fragezeichen ?. Außerdem in TCC Sie können einen Zeichensatz angeben (siehe unten).
WARNUNG: Wenn Sie einen Platzhalter verwenden, suchen Sie nach Dateien, die in einem Befehl wie verarbeitet werden sollen FÜR or DOund Sie neue Dateinamen erstellen (sei es durch Umbenennen vorhandener Dateien oder durch Erstellen neuer Dateien), stimmen die neuen Dateinamen möglicherweise mit Ihrem Auswahlplatzhalter überein und veranlassen Sie, sie erneut zu verarbeiten.
Sternchen * Platzhalter
An Sternchen * in einer Dateispezifikation bedeutet „ein Satz beliebiger Zeichen oder kein Zeichen an dieser Position“. Der folgende Befehl zeigt beispielsweise eine Liste aller Dateien an (einschließlich Verzeichnissen, jedoch mit Ausnahme derjenigen Dateien und Verzeichnisse mit mindestens einem der Attribute). versteckt und System) im aktuellen Verzeichnis:
sagen *
Wenn Sie alle Dateien mit a sehen möchten .TXT Erweiterung:
dir*.txt
Wenn Sie wissen, dass die gesuchte Datei einen Basisnamen hat, der mit beginnt ST und eine Erweiterung, die mit beginnt .D, Sie können es so finden. Dateinamen wie STATE.DAT, STEVEN.DOC, und ST.D werden alle angezeigt:
dir st*.d*
TCC Sie können außerdem das Sternchen verwenden, um Dateinamen mit bestimmten Buchstaben irgendwo im Namen abzugleichen. Im folgenden Beispiel wird jede Datei mit a angezeigt .TXT Erweiterung, die die Buchstaben enthält AM irgendwo innerhalb seines Basisnamens zusammen. Es wird beispielsweise angezeigt AMPLE.TXT, STAMP.TXT, CLAM.TXT und AM.TXT, aber es wird ignoriert CLAIM.TXT:
dir *am*.txt
Fragezeichen ? Platzhalter
A Fragezeichen ? entspricht jedem einzelnen Dateinamenzeichen. Sie können das Fragezeichen an einer beliebigen Stelle in einem Dateinamen platzieren und so viele Fragezeichen verwenden, wie Sie benötigen. Im folgenden Beispiel werden Dateien mit Namen wie angezeigt BRIEF.DOC, LETTER.DAT, und LITTER.DU:
dir l?tter.d??
Die Verwendung eines Sternchen-Platzhalters vor anderen Zeichen und der unten erläuterten Zeichenbereiche stellen Verbesserungen der standardmäßigen Microsoft-Platzhaltersyntax dar und funktionieren wahrscheinlich nicht ordnungsgemäß mit anderer Software als TCC.
„Zusätzliche“ Fragezeichen in Ihrer Wildcard-Angabe werden ignoriert, wenn der Dateiname kürzer als die Wildcard-Angabe ist. Wenn Sie beispielsweise Dateien aufgerufen haben BRIEF.DOC, BRIEF1.DOC und BRIEF.DOC, dieser Befehl zeigt alle drei Namen an:
dir Brief?.doc
Die Datei BRIEF.DOC ist in der Anzeige enthalten, da am Ende das „zusätzliche“ Fragezeichen steht BRIEF? wird beim Abgleich mit dem kürzeren Namen ignoriert LETTER.
Platzhalter für Zeichensätze
In einigen Fällen, die ? Platzhalter ist möglicherweise zu allgemein. TCC (aber nicht CMD) Außerdem können Sie durch die Verwendung von eckigen Klammern den genauen Satz von Zeichen angeben, die Sie an einer bestimmten Position im Dateinamen akzeptieren (oder ausschließen) möchten []. In die Klammern können Sie die einzelnen zulässigen Zeichen oder Zeichenbereiche einfügen. Zum Beispiel, wenn Sie eine Übereinstimmung wünschen BRIEF0.DOC bis BRIEF9.DOC, könnten Sie diesen Befehl verwenden:
Dir Brief[0-9].doc
Auf diese Weise können Sie alle Dateien finden, deren Name einen Vokal als zweiten Buchstaben enthält. Dieses Beispiel zeigt auch, wie die Platzhalterzeichen gemischt werden:
dir ?[aeiouy]*
Sie können eine Gruppe von Zeichen oder einen Zeichenbereich ausschließen, indem Sie ein Ausrufezeichen verwenden [!] als erstes Zeichen in den Klammern. In diesem Beispiel werden alle Dateinamen angezeigt, die mindestens zwei Zeichen lang sind, mit Ausnahme derjenigen, deren Name einen Vokal als zweiten Buchstaben enthält:
dir ?[!aeiouy]*
Das nächste Beispiel, das Dateien wie auswählt AIP, BIP und TIPP aber nicht NIPdemonstriert, wie Sie mehrere Bereiche innerhalb der Klammern verwenden können. Es wird eine Datei akzeptiert, die mit einem beginnt A, B, C, D, T, U, oder V:
dir [a-dt-v]ip
Sie können in den Klammern ein Fragezeichen verwenden, dessen Bedeutung sich jedoch geringfügig von der eines normalen Fragezeichen-Platzhalters (ohne Klammer) unterscheidet. Ein normaler Fragezeichen-Platzhalter stimmt mit jedem Zeichen überein, wird jedoch ignoriert, wenn ein Name gefunden wird, der kürzer als die Platzhalterspezifikation ist, wie oben beschrieben. Ein Fragezeichen in eckigen Klammern stimmt mit jedem Zeichen überein nicht werden verworfen, wenn kürzere Dateinamen abgeglichen werden. Zum Beispiel:
dir Buchstabe[?].doc
wird angezeigt BRIEF1.DOC und BRIEF.DOC, Aber nicht BRIEF.DOC.
Sie können jedes der Platzhalterzeichen in jeder gewünschten Kombination innerhalb eines einzelnen Dateinamens wiederholen. Der folgende Befehl listet beispielsweise alle Dateien auf, die ein haben A, B, oder C als drittes Zeichen, gefolgt von null oder mehr zusätzlichen Zeichen, gefolgt von einem D, E, oder F, optional gefolgt von einigen zusätzlichen Zeichen und einer Erweiterung, die mit beginnt P or Q. Wahrscheinlich müssen Sie nichts so Komplexes tun, aber wir haben es eingefügt, um Ihnen die Flexibilität erweiterter Platzhalter zu zeigen:
dir ??[abc]*[def]*.[pq]*
Sie können auch die Platzhaltersyntax in eckigen Klammern verwenden, um einen Konflikt zwischen langen Dateinamen mit Semikolons zu umgehen [;] und die Verwendung eines Semikolons zur Angabe von Liste einschließen. Wenn Sie beispielsweise eine Datei auf einem LFN-Laufwerk mit dem Namen haben C:\DATA\LETTER1;V2 und Sie geben diesen Befehl ein:
del \data\letter1;v2
Sie werden nicht die Ergebnisse erzielen, die Sie erwarten. Anstatt die genannte Datei zu löschen, TCC werde versuchen zu löschen BRIEF1 und dann V2, weil das Semikolon ein angibt Liste einschließen. Wenn Sie jedoch eckige Klammern um das Semikolon verwenden, wird es als Dateinamenzeichen und nicht als Trennzeichen für die Include-Liste interpretiert. Dieser Befehl würde beispielsweise die oben genannte Datei löschen:
del \data\letter1[;]v2
Passende kurze Dateinamen (SFNs)
Wenn die Konfigurationsoption „Nach SFNs suchen“ aktiviert ist, in TCC Platzhaltersuchen akzeptieren eine Übereinstimmung auf beiden LFN or die SFN, um dem Verhalten von zu entsprechen CMD. Dies kann dazu führen, dass einige Dateien nur aufgrund der SFN-Übereinstimmung gefunden werden. In den meisten Situationen ist dies eigentlich nicht erwünscht und kann durch Deaktivieren der Option vermieden werden (der Standard).
Hinweis: Die Wildcard Der Expansionsprozess wird versuchen, beides zu ermöglichen CMD-style „Erweiterung“-Matching (nur eine Erweiterung am Ende des Wortes) und die erweiterte TCC Dateinamensübereinstimmung (ermöglicht Dinge wie *.*.abc), wenn im Ziel von a ein Sternchen gefunden wird COPY, MOVE or REN / UMBENENNEN Befehl.
Platzhalter in Verzeichnisnamen
TCC (aber nicht CMD) unterstützt Platzhalter in den Verzeichnisnamen (aber nicht im Laufwerksnamen) für intern TCC Befehle und Funktionen. Diese Arten von Platzhaltern kommen unter Linux häufig vor, werden jedoch in CMD und den meisten Windows-Apps nicht unterstützt.
Sie können die Rekursion des Unterverzeichnisses steuern, indem Sie Folgendes angeben * or ** in dem Weg. A * entspricht einer einzelnen Unterverzeichnisebene; A ** stimmt mit allen Unterverzeichnisebenen für diesen Pfadnamen überein. Verzeichnisplatzhalter unterstützen auch reguläre Ausdrücke. Verzeichnis-Platzhalter können nicht mit der Option /O:... verwendet werden (die Einträge sortiert, bevor der Befehl ausgeführt wird). Und denken Sie sorgfältig darüber nach, bevor Sie Verzeichnis-Platzhalter mit der Option /S (rekursive Unterverzeichnisse) verwenden, da dies mit ziemlicher Sicherheit zu unerwarteten Ergebnissen führt!
Zum Beispiel, um die Datei zu löschen foobar in einem beliebigen Unterverzeichnis von c:\test\test2 (aber nicht in einem ihrer Unterverzeichnisse):
del c:\test\test2\*\foobar
Um die Datei zu löschen foobar in jedem Unterverzeichnis unter c:\test (und allen Unterverzeichnissen), dessen Name irgendwo „foo“ enthält:
del c:\test\**\*foo*\foobar
Um die Datei zu löschen foobar in einem beliebigen Unterverzeichnis von c:\test, das mit a beginnt t und endet mit a 2:
del c:\test\t*2\foobar
Es gibt einige Befehle, die Verzeichnis-Platzhalter nicht unterstützen, da diese bedeutungslos oder destruktiv wären (z. B. TREE, @FILEOPEN, @FILEDATE usw.).
Reguläre Windows-Ausdrücke in TCC
Zusätzlich zu erweitert Windows-Platzhalter (*, ?, Und [...]), TCC unterstützt die Verwendung von Platzhalter für reguläre Ausdrücke zum Abgleichen und Ersetzen von Dateinamen in internen Dateiverwaltungsbefehlen (COPY, DEL, DIR, MOVE, REN usw.). Sie können die Syntax des regulären Ausdrucks auswählen, die Sie verwenden möchten: TCC unterstützt reguläre Ausdrücke von Perl, Ruby, Java, grep, POSIX, gnu, Python und Emacs.
Die Syntax lautet:
::regex
Beispielsweise:
dir ::ca[td]
Beachten Sie, dass mit Reguläre Windows-Ausdrücke verlangsamt Ihre Verzeichnissuche etwas – da Windows sie nicht nativ unterstützt TCC Der Parser muss den Dateinamen in konvertieren *, rufen Sie alle Dateinamen ab und ordnen Sie sie dann dem regulären Ausdruck zu.
Wenn Ihr regulärer Ausdruck Sonderzeichen (Leerzeichen, Umleitungszeichen, Escape-Zeichen usw.) enthält, müssen Sie diese in doppelte Anführungszeichen setzen. Zum Beispiel:
dir "::^\w{1,8}\.btm$"
Für weitere Informationen über Platzhalter für reguläre Ausdrücke Syntax, siehe Syntax für reguläre Ausdrücke der Take Command helfen.
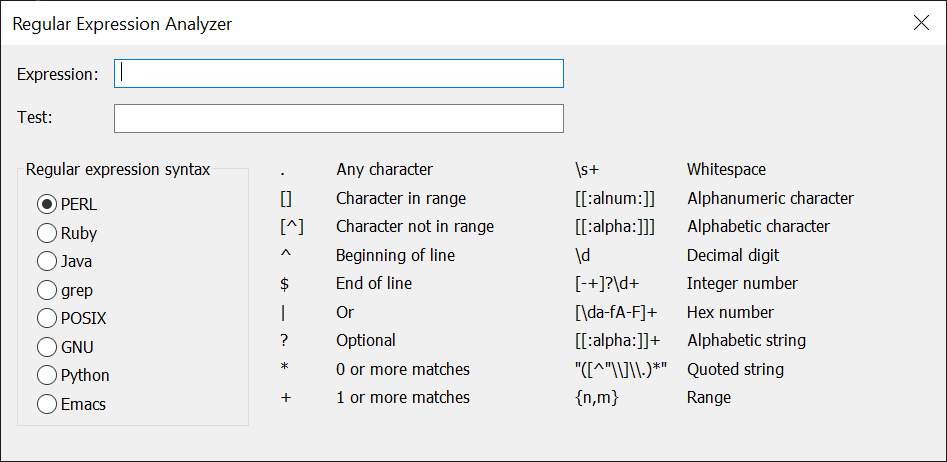
Um die Erstellung und das Testen regulärer Ausdrücke zu vereinfachen, bietet TAke Command und TCC Fügen Sie ein Dialogfeld zur Analyse regulärer Ausdrücke hinzu (Strg-F7 aus dem TCC Befehlszeile oder im Menü „Extras“ in Take Command.) Es gibt zwei Bearbeitungsfelder:
- Die erste besteht darin, den regulären Ausdruck zu testen. Wenn der reguläre Ausdruck gültig ist, wird im Dialogfeld ein grünes Häkchen rechts neben dem Bearbeitungsfeld für den Ausdruck angezeigt. Wenn der reguläre Ausdruck ungültig ist, wird im Dialogfeld ein rotes X angezeigt.
- Das zweite Bearbeitungsfeld ist für den Text, den Sie mit dem regulären Ausdruck abgleichen möchten. Wenn der Text mit dem regulären Ausdruck übereinstimmt, wird im Dialogfeld rechts neben dem Testbearbeitungsfeld ein grünes Häkchen angezeigt. Wenn der Text nicht übereinstimmt, wird im Dialogfeld ein rotes X angezeigt.